Computers / PC Components
Software Optimization Guide for AMD Family 10h Processors
A comprehensive software optimization guide for AMD Family 10h processors, covering C/C++ source-level optimizations, 64-bit performance, instruction decoding, cache and memory management, branch and scheduling optimizations, SIMD and x87...
Table of contents
Manual images
Click an image to enlargeQuick guide from the manual
This document is a technical optimization guide for software developers, compiler designers, and assembly language programmers working with AMD Family 10h processors. It provides specific recommendations to improve code performance, including source-level optimizations, instruction-decoding strategies, and memory management techniques.
C and C++ Source-Level Optimizations
This section provides guidelines for writing efficient C and C++ code. Key recommendations include:
- Use array notation instead of pointer notation to reduce aliasing.
- Completely unroll small loops with fixed iteration counts.
- Arrange boolean operands in logical expressions to take advantage of short-circuit evaluation.
- Sort and pad structures to achieve natural alignment.
- Use the const type qualifier for objects that do not change.
General 64-Bit Optimizations
Focuses on improving performance for software running in 64-bit mode. Key points include:
- Use 64-bit registers for 64-bit integer arithmetic.
- Use 128-bit media instructions (SSE, SSE2, SSE3, SSE4a) instead of x87 or 64-bit media instructions for floating-point operations.
- Use 32-bit legacy general-purpose registers (EAX through ESI) for unsigned integers that do not require 64-bit range to avoid REX prefix overhead.
Instruction-Decoding Optimizations
Designed to maximize the number of instructions the processor can decode per cycle:
- Use DirectPath instructions instead of VectorPath instructions.
- Use load-execute instructions for integer and floating-point computations.
- Align branch targets to 32-byte boundaries.
- Use 8-bit sign-extended immediate values and displacements to improve code density.
Cache and Memory Optimizations
Covers strategies to utilize L1 caches and high-bandwidth buses effectively:
- Avoid memory-size mismatches between stores and dependent loads.
- Ensure data objects are naturally aligned.
- Avoid store-to-load dependencies.
- Use prefetch instructions to increase effective bandwidth.
- Avoid placing code and data in the same 64-byte cache line.
Branch Optimizations
Focuses on improving branch prediction and minimizing penalties:
- Align branch targets to 32-byte boundaries.
- Use three-byte return-immediate RET instructions.
- Avoid conditional branches that depend on random data.
- Use muxing constructs to simulate conditional moves in SSE/MMX code.
Scheduling Optimizations
Discusses improving instruction scheduling:
- Select instructions with shorter latencies.
- Use loop unrolling to increase instruction-level parallelism.
- Inline functions that are called from a single site and contain fewer than 25 machine instructions.
- Avoid address-generation interlocks by scheduling independent loads/stores.
Optimizing with SIMD Instructions
Provides guidance on using SSE, SSE2, SSE3, and SSE4a instructions:
- Align all packed floating-point data on 16-byte boundaries.
- Use explicit load instructions (MOVSD, MOVSS).
- Use XOR operations (XORPS, XORPD) to negate operands instead of multiplication.
- Use instructions that perform XOR operations to clear MMX and XMM registers.
Multiprocessor Considerations
Discusses ccNUMA configurations and multithreading:
- Schedule threads to maintain balanced system load.
- Keep data accessed by a thread local to the node on which the thread runs.
- Avoid false data sharing by enforcing 64-byte alignment during allocation.
- Use streaming stores for write-only buffers.
Optimizing Secure Virtual Machines
Covers virtualization optimizations:
- Use nested paging instead of shadow paging.
- Avoid unnecessary state swapping (VMSAVE, VMLOAD).
- Intercept as few MSRs, events, and instructions as possible.
Practical help
Common problems
Store-to-load forwarding stalls
Align memory accesses and match addresses and sizes of stores and dependent loads.
Branch mispredictions
Arrange boolean operands for quick evaluation and avoid dense conditional branches.
Cache thrashing
Avoid placing code and data in the same 64-byte cache line.
Before use
- Identify performance hot spots using profiling tools.
- Ensure code is targeted for AMD Family 10h architecture.
- Review compiler optimization settings.
- Verify data alignment requirements.
Images and diagrams
- Figure 8 shows the block diagram of the AMD Family 10h processor.
- Figure 9 illustrates the integer execution pipeline.
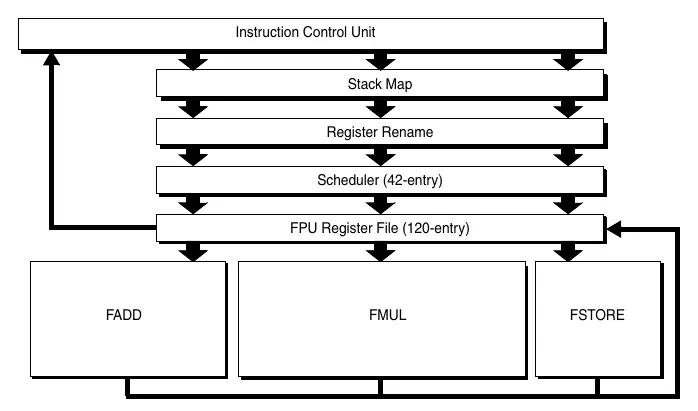
- Figure 10 shows the floating-point unit dataflow.
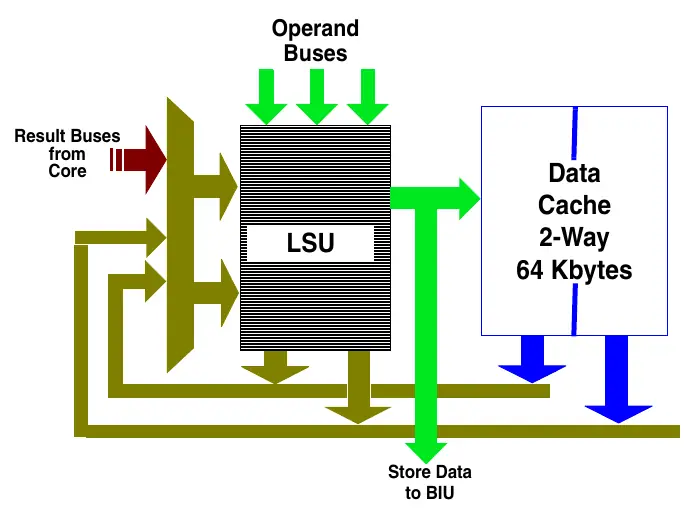
- Figure 11 details the load-store unit.
Model compatibility
- Optimizations are specific to AMD Family 10h processors.
- Some optimizations apply only to 32-bit or 64-bit software as noted in each section.

Manual page author
Michael Turner
Technical manual editor
Reviews PDF manuals for structure, safety notes, and practical product details so readers can find the right information quickly.